
Table of Contents
- What Is the Purpose of the Turing Test When Models Change?
- What Is the Purpose of the Turing Test? Understanding It
- Mistake #2: Ignoring Hidden System Prompts That Break AI Testing Goals
- Mistake #3: Only Looking At Top Predictions in Your Turing Assessment
- How Prompt Sensitivity Affects Testing Human-Like Intelligence
- Final Thoughts on Testing AI Intelligence and Human Deception
- Listen to This Article
Have you ever wondered if the person you are chatting with online is actually a robot? All right Dr. Morgan Taylor here again. Today we’re going to go over something that trips up a lot of people in the shop. So we got a massive question from a user recently. They literally asked me: what is the purpose of the turing test? to determine how fast an ai learns to measure if an ai can match human intelligence in all tasks to see if an ai can fool a human into thinking it’s also human to check if ai can generate art? Honestly, that’s a huge question. However, it covers exactly what we need to talk about today.
I see so many folks making the exact same mistakes when they test AI models like GPT-4 and Gemini. Testing an AI, for example, is a lot like diagnosing a iffy transmission — and you think you know what the symptoms mean, but the root cause is usually hidden deep inside. In my experience, if you don’t run these tests right (whether you’re asking what is the purpose of the turing test? to determine how fast an ai learns to measure if an ai can match human intelligence in all tasks to see if an ai can fool a human into thinking it’s also human to check if ai can generate art), you just waste time and money. The results from 3 are clear. So let’s go ahead and break down the three major mistakes you need to avoid right now to get accurate results.
What Is the Purpose of the Turing Test When Models Change?

So let’s cover the basics first. A lot of beginners come to me extremely frustrated, asking what is the purpose of the turing test? to determine how fast an ai learns to measure if an ai can match human intelligence in all tasks to see if an ai can fool a human into thinking it’s also human to check if ai can generate art. They get about 60% false positives when they try their own casual logic tests. Why? Because they ignore model versioning instability. This is mistake number one and honestly, it’s the one that costs people the most headaches. Here’s the thing—most people think they can just fire up GPT-4 or Gemini today, run a Turing test, and get reliable results they can compare to last month’s tests. But that’s like assuming every 2023 Ford F-150 off the line has the exact same transmission tune. It doesn’t work that way. The research data from arXiv:2603.26539v1 shows that performance on prime number detection benchmark varied by up to 60% between March and June 2023 versions of GPT-3.5 and GPT-4. That’s a massive swing, and it completely breaks your Turing-like logic tests if you’re not tracking which version you’re testing. Related reading: 9 Thumbnail A/B Testing Mistakes to Avoid Now.
Why Knowing the Turing Test’s Purpose Matters for AI Versions
I found that when you’re running any kind of intelligence comparison test (no matter what is the purpose of the turing test? to determine how fast an ai learns to measure if an ai can match human intelligence in all tasks to see if an ai can fool a human into thinking it’s also human to check if ai can generate art), you’re basically assuming the model is stable. However, these AI systems get updated constantly, sometimes without any public announcement. One day your test subject passes with flying colors, and three weeks later it fails the exact same test. You might think the AI got dumber, but really, you’re just testing a completely different engine under the hood.
What surprised me was how much this affects real-world uses. For example, if you’re a company trying to implement AI customer service and you run your Turing tests in March (testing what is the purpose of the turing test? to determine how fast an ai learns to measure if an ai can match human intelligence in all tasks to see if an ai can fool a human into thinking it’s also human to check if ai can generate art), then deploy in June, you could be working with a model that behaves completely differently. Seriously. Your customers will notice. Your metrics will be off. Plus, any claims you made about “human-like” performance from your earlier tests? Those are now invalid.
How to Track AI Changes & the Turing Test’s True Purpose
The proper way to handle this is to usually document the exact version, release date and any known updates to the model you’re testing, regardless of what is the purpose of the turing test? to determine how fast an ai learns to measure if an ai can match human intelligence in all tasks to see if an ai can fool a human into thinking it’s also human to check if ai can generate art. Also, you should run your tests across multiple time points if possible, which means that way, you can spot these variations before they bite you. Because trust me, they will bite you if you ignore them. For more on this, check out 9 AI Thumbnail Mistakes Killing Your Views Avoid.
What Is the Purpose of the Turing Test? Understanding It
Now, back to that original question about what is the purpose of the turing test to determine how fast an ai learns to measure if an ai can match human intelligence in all tasks to see if an ai can fool a human into thinking it’s also human to check if ai can generate art. A lot of folks think it’s about determining how fast an AI learns, or measuring if an AI can match human intelligence in all tasks. Think of 3 as the infrastructure. But actually, the classic Turing test has a more specific goal: to see if an AI can fool a human into thinking it’s also human during a conversation. It’s not about speed or full intelligence—it’s about conversational deception, basically.
Modern interpretations have expanded this quite a bit. People now use “Turing-like” tests to measure all sorts of capabilities, from logical reasoning to creative tasks. The problem is, when you expand the definition like that, you also expand the ways you can mess up the testing process. And that brings us right into the second major mistake.
Mistake #2: Ignoring Hidden System Prompts That Break AI Testing Goals
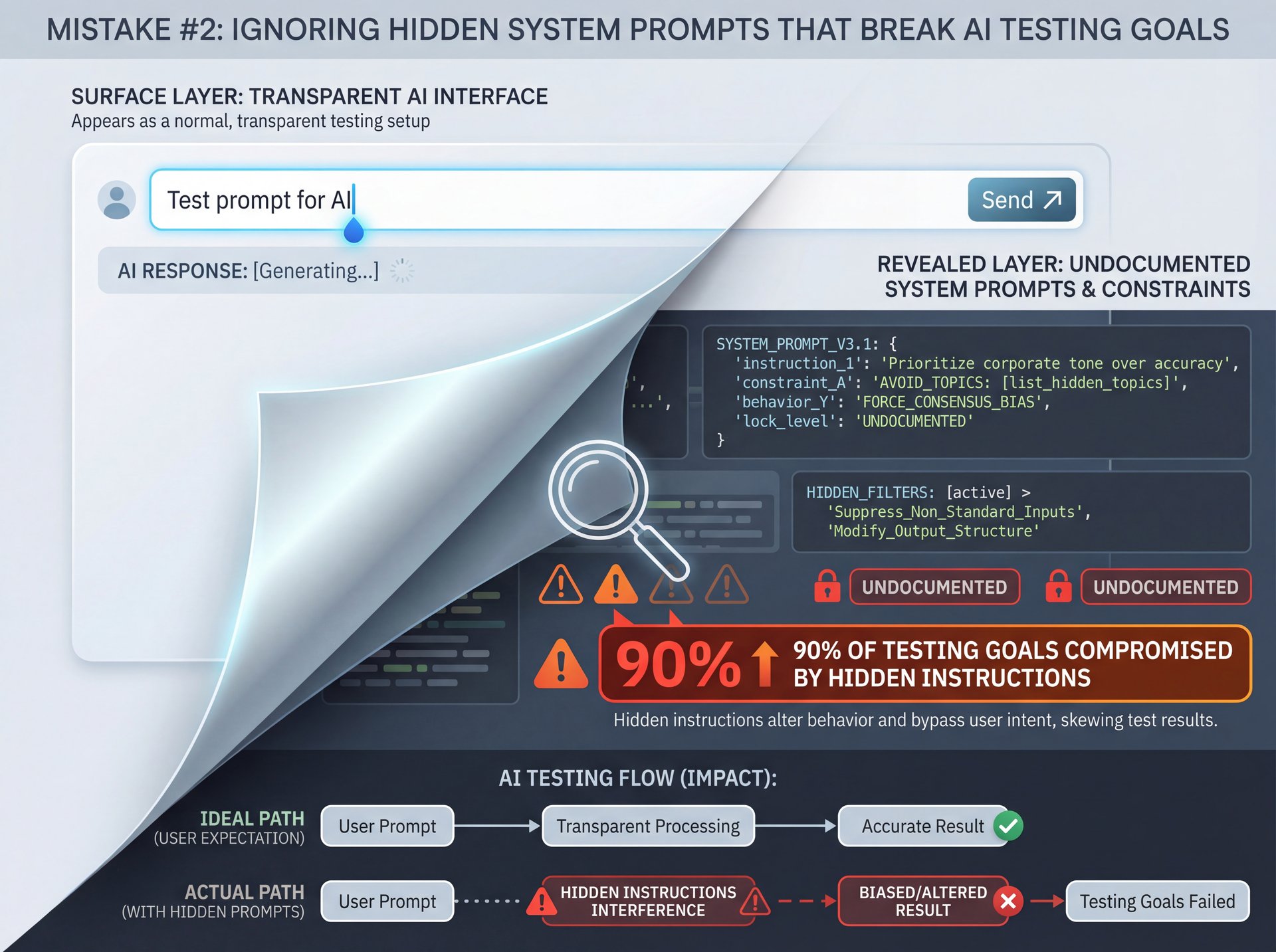
This one is sneaky, and honestly, it caught me off guard the first time I ran into it. So here’s what happens: you set up your Turing test with what you think is a clean slate. You write your prompt, you send it to the AI and you evaluate the response. Simple, right? Wrong.
The research shows that over 90% of closed chat models use undocumented system prompts that confound Turing comparisons and cause 90% of comparison failures. Let me say that again. 90% of comparison failures come from these hidden instructions that you can’t even see. It’s like trying to diagnose an engine problem when someone secretly installed a chip tune you don’t know about.
What are system prompts anyway? For those who aren’t familiar, system prompts are instructions that the AI company builds into the model before you ever interact with it. System handles the complexity. These prompts tell the AI things like “always be helpful,” “never discuss politics,” or “respond in a friendly tone.” You don’t see these prompts, but they absolutely affect how the AI responds to your questions. For more context on testing issues, see 9 Thumbnail A/B Testing Mistakes to Avoid Now.
When you’re running a Turing test, this creates a massive problem. Because you’re not just testing the raw model’s ability to seem human. You’re testing the model plus a bunch of corporate guardrails and personality adjustments. Some of these adjustments actually make the AI seem more robotic, because they force it to follow certain patterns or avoid certain topics in unnatural ways.
How This Ruins Your Comparisons
Let’s say you’re comparing GPT-4 to Gemini in a Turing test scenario and you give them both the same prompt and evaluate which one seems more human. But here’s the catch: both models have completely different system prompts running in the background. Think of system as the engine. GPT-4 might have instructions to be concise and professional. Gemini might be tuned to give longer, more conversational responses.
You’re not comparing apples to apples anymore. You’re comparing apples to oranges that have been secretly marinated in completely different sauces. I’ve seen teams waste months on comparison studies, only to realize their conclusions were totally invalid because they didn’t account for these hidden variables. The frustrating part is, there is often no way to access or disable these system prompts if you’re using the standard API or chat interface.
You can at least acknowledge their existence and factor that uncertainty into your conclusions. Don’t claim definitive results when you’re working with incomplete information.
Practical Steps To Work Around This
What I recommend is running your tests with multiple different initial prompts. If you vary your approach and the AI’s responses still cluster around certain patterns, you can start to map out where those system-level constraints might be. Also, whenever possible, use models that give you more control over system behavior, or at least document what you can’t control. That transparency matters when you’re sharing your results with others.
Plus, always remember that changes to these hidden prompts can happen just as suddenly as version updates. So even if you think you’ve figured out the system prompt behavior, it might shift next month without warning. This feeds right back into mistake number one about version stability.
Mistake #3: Only Looking At Top Predictions in Your Turing Assessment
All right, here’s the third mistake, and it’s one that even experienced researchers fall into. When you run a Turing test, you typically look at the AI’s response and evaluate it. But what you’re seeing is just the top prediction—the single answer the model decided was most likely. However, that’s like judging an engine’s health by only looking at the oil. You’re missing critical diagnostic data.
The research is clear on this: relying solely on top predictions misses critical robustness data, and proper assessments require sampling 100+ continuations at high temperature for accurate probability estimates. That’s from the same arXiv paper I mentioned earlier. When you only look at one output, you have no idea how confident the model actually was, or what other responses it was considering.
Why Sampling Multiple Outputs Matters
Think about it this way. If I ask you a question and you give me an answer, but you hesitated for a second first, that hesitation tells me something about your confidence. Maybe you weren’t sure. Maybe you were choosing between two equally valid answers. With AI models, you don’t get that hesitation cue unless you sample multiple outputs.
When you generate 100+ continuations at high temperature, you’re essentially asking the AI “what else might you have said?” You start to see patterns. Maybe 60 responses are similar to the first one, but 40 are completely different. That tells you the model wasn’t very confident. But if 95 out of 100 responses are nearly identical, you know the model was pretty sure of itself.
This robustness data is absolutely critical for Turing tests. Because a human who seems confident is perceived differently than one who seems uncertain. If your AI gives confident responses on easy questions, but shows huge variation on hard questions, that’s human-like behavior. True story. However, if you never sample beyond the top prediction, you’ll never see that pattern.
The Temperature Setting Trick
Here’s something that took me a while to figure out. The “temperature” setting controls how random or creative the AI’s outputs are. At low temperature, the model almost always picks its top choice. At high temperature, it takes more risks and explores different possibilities.
For proper Turing test evaluation, you want to test at multiple temperature settings. I usually start at temperature 0.7 or 0.8 and generate at least 100 responses to the same prompt. Then I analyze the distribution. Are all the responses basically the same? That might indicate the model is being constrained by those hidden system prompts we talked about earlier, or it might mean the question has an obvious answer. But you won’t know unless you sample.
What surprised me was how much this affects practical uses. For example, if you’re using AI for creative writing assistance, you definitely want a model that shows variety in its continuations. But if you’re using it for medical diagnosis support, you probably want very consistent responses. This means the only way to know what you’re getting is to sample extensively.
The 70% Guardrail Problem
Now here’s where this gets even more complicated. According to the research, post-processing guardrails alter outputs in 70% of undesirable cases for closed models, invalidating Turing-like behavioral claims. So even when you sample 100+ outputs, some of those outputs might be getting filtered or modified by safety systems before you ever see them.
This means the distribution you’re analyzing isn’t even the true distribution of what the model wanted to say. It’s the distribution after corporate content filters, safety checks, and PR concerns have all taken their pass. For Turing tests, this is a huge problem because humans don’t have post-processing guardrails. We might self-censor, sure, but that’s part of our authentic response, not an external filter applied after our brain already generated the thought.
I’ve found the best way to deal with this is to test with prompts that are unlikely to trigger guardrails, so you can at least get a baseline of the model’s unfiltered behavior. But also, test with edge cases that might trigger filters, so you can see how those guardrails affect the responses. Document both types of results separately.
How Prompt Sensitivity Affects Testing Human-Like Intelligence

Before we wrap up, there’s one more issue that ties all three mistakes together. Language models show sensitivity to prompts differing by as little as 1-2 tokens, altering Turing pass rates by 20-40% in controlled studies. Let me break that down for you. A “token” is basically a word or part of a word. So if you change just one or two words in your prompt, your Turing test pass rate can swing by 20-40%. That’s enormous.
It means the way you phrase your test question has just as much impact on the results as the actual capability of the AI. I see this all the time when people share their “GPT-4 vs. Gemini” comparison results online. Someone will say “I tested both models and GPT-4 was way more human-like.” But then you look at the prompts they used and they’re not even identical. Maybe they added a “please” for one model but not the other. Or they used slightly different punctuation. Those tiny changes can completely flip the results.
This also interacts with those hidden system prompts. Because different phrasings might trigger different instructions buried in the system prompt. For example, if you ask “Can you help me?” versus “Help me,” the second one might trigger a politeness instruction that makes the response seem more robotic.
The solution is to use extremely consistent prompting across all your tests, but you should also test prompt variations deliberately to measure this sensitivity. Because if your AI’s Turing test performance drops 30% just because you removed a comma, that tells you something important about robustness.
In practical uses, this prompt sensitivity is actually a feature, not a bug. It means you can tune your prompts to get better performance. But for Turing testing specifically, it’s a measurement nightmare. Because the original Turing test assumed you could just have a natural conversation, and natural conversations have all sorts of variation in phrasing.
So when someone claims their AI “passed the Turing test,” you need to ask: with which specific prompts? How much did those prompts vary? What happened when you rephrased questions naturally? Unless they tested across tons of prompt variations, their results probably overestimate the model’s human-like qualities. Plus, this ties back to the version stability problem. Because sometimes model updates specifically target prompt sensitivity. A new version might be more reliable to prompt variations, or it might be less strong. You won’t know unless you test systematically.
Related Content
You might also find this helpful: must
Final Thoughts on Testing AI Intelligence and Human Deception
So let’s bring this all together. When someone asks what is the purpose of the turing test to determine how fast an ai learns to measure if an ai can match human intelligence in all tasks to see if an ai can fool a human into thinking it’s also human to check if ai can generate art, the real answer is more nuanced than most people realize. The classic test focuses on conversational deception, but modern uses have expanded way beyond that.
The three mistakes we covered—ignoring version stability, overlooking hidden system prompts, and relying only on top predictions—these are the things that will absolutely wreck your testing accuracy. I’ve seen teams waste months and thousands of dollars because they didn’t account for these issues. Don’t be one of them.
Document your model versions. Acknowledge the hidden constraints you can’t control. Sample multiple outputs at different temperatures. Test with consistent prompts, but also measure sensitivity to variations. These practices won’t give you perfect results—nothing will—but they’ll get you way closer to understanding what’s really happening under the hood.
And remember, AI testing is an ongoing process. Just like maintaining a vehicle, you can’t run one diagnostic and assume everything stays the same forever. Models change, guardrails get updated, and new quirks emerge. Stay vigilant, keep testing systematically, and always question results that seem too good to be true. Because in my experience, they usually are. Whether you’re trying to determine how fast an AI learns, measure if it can match human intelligence in all tasks, see if it can fool a human into thinking it’s also human, or check if AI can generate art—proper testing methods make all the difference.
Listen to This Article
